Questo documento propone un’implementazione dell’algoritmo di Reinforcement Learning nell’ambito di un progetto dello sviluppo di un software di bot-trading. Non si tratta di una versione definitiva, ma soltanto di un prototipo con tutti i difetti del caso. In questo articolo partiremo con una versione già sviluppata e cercheremo di migliorarla integrando un idea di “calcolo della sensibilità”.
Lo stato di fatto dell’algoritmo di Reinforcement Learning sviluppato per l’algoritmo di bot trading.
Avendo già sviluppato un algoritmo di Reinforcement Learning partiamo dall’analisi di alcuni risultati e in particolare leggiamo i seguenti grafici.

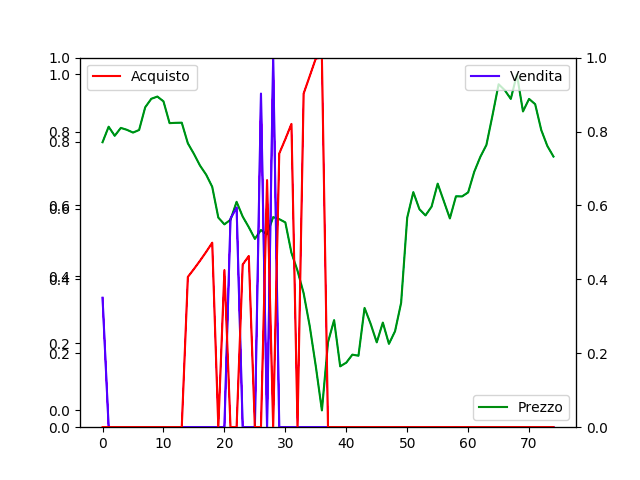
(Risultato del funzionamento della prima versione dell’algoritmo)
Il grafico presente in figura uno, mostra l’andamento del prezzo (linea di colore verde) di una pair (ETH/BTC) nell’ambito di un Exchange (mercato) di cryptovalute. Come si legge, l’acquisto (linea di colore rosso) avviene nel momento corretto e cresce con l’aumentare del minimo locale del prezzo (linea di colore verde), al contrario la vendita (linea di colore blu) cresce con l’aumento del massimo locale del prezzo. L’algoritmo di Reinforcement Learning non è ancora perfetto, e se notate, non sempre il massimo dell’acquisto o della vendita coincide con il minimo del prezzo dell’andamento della pair o con il massimo dell’andamento della pair. Inoltre, non è detto che in altre condizioni di mercato, tale algoritmo conservi tale risultato.
(Secondo risultato del funzionamento della prima versione dell’algoritmo)
Anche il secondo grafico evidenzia come ad un minimo del prezzo dell’andamento della pair vi sia un massimo di acquisto. Inoltre, si evidenzia come il massimo della vendita del grafico in tali condizioni di mercato aumenti in un massimo relativo. Tale condizione potrebbe non risultare soddisfacente al fine di ottenere un risultato ottimale.
Lo Stato dell’algoritmo di Reinforcement Learning.
Per quanto concerne la prima versione dell’algoritmo di Reinforcement Learning (Q-Learning), lo stato della moneta viene individuato da quattro indicatori: Aroon Up, Aroon Down, RSI, ADX. Questi , costituiscono ad ogni prezzo della pair uno stato ben preciso della moneta. Quest’ultimo, così definito, viene salvato in una tabella (bot_qvalue) all’interno di un database MYSQL insieme ai valori di acquisto, vendita e assenza di segnale. Ovviamente, l’algoritmo di Reinforcement Learning dovrebbe “apprendere” quando è il momento più opportuno per vendere e acquistare e tale condizione varia al passare del tempo e all’acquisizione di “nuova conoscenza”, ossia al verificarsi di nuove condizioni di mercato.
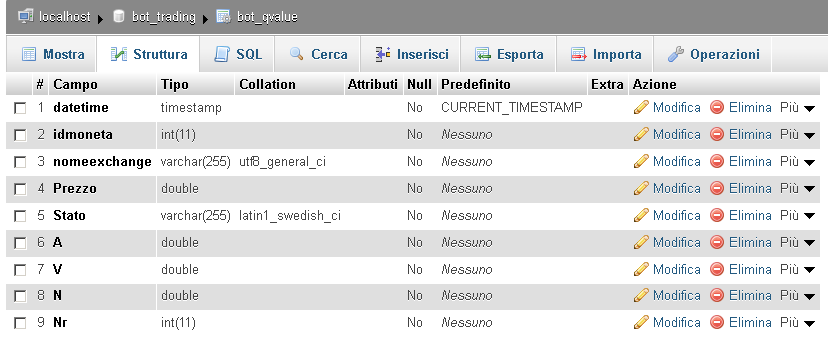
(Tabella bot_qvalue di salvataggio dei valori eleborati dall’algoritmo di Reinforcement Learning).
Nella tabella mostrata nell’immagine tre, il campo “idmoneta” viene valorizzato con il valore della pair, per esempio, ‘ETH/BTC’ o ‘ETH/USDT’, Il campo “nomeexchange” con il valore del mercato selezionato, esempio, ‘BINANCE’, il campo del prezzo non ha bisogno di spiegazioni, mentre il campo “Stato”, è definito dalla stringa proveniente dai quattro indicatori di cui abbiamo già parlato. Il campo “A” non è altro che il valore attribuito all’acquisto in quel particolare “Stato”, il campo “V” il valore attribuito alla Vendita in quel particolare “Stato” e infine al campo N è assegnato un valore quando l’azione non è di vendita e non è di acquisto a un determinato “Stato”.
Ogni record presente nella tabella bot_qvalue presenta un valore di acquisto o di vendita o nullo elaborato dall’algoritmo di Reinforcement Learning in un particolare “Stato”.
Definizione della sensibilità dell’algoritmo di Reinforcement Learning.
Per ogni stato vi sarà un valore massimo di acquisto e di vendita, ma non è possibile acquistare a tutti gli stati di acquisto e neppure vendere a tutti gli stati di vendita quindi, dovrò in qualche modo determinare una “sensibilità” della scelta dello “Stato”. Una sensibilità più alta determinerà un maggior numero di movimenti dati da un insieme di stati scelto più numeroso, e al contrario una sensibilità più bassa determinerà meno movimenti, ma un probabile profitto maggiore.

(Discorso del calcolo della sensibilità dell’algoritmo di Reinforcement Learning)
Come si vede nell’immagine precedente, per sensibilità, si intende il range entro il quale un programma “Trader” processa i dati dei segnali di acquisto e di vendita, e li esegue effettivamente. Con una sensibilità più alta, se il segnale, è di acquisto, prenderò in considerazione lo stato A1,A2,A3,A4. Con una sensibilità più bassa prenderò in considerazione solo alcuni stati A3,A4 (sempre in acquisto). Quindi la variabile sensibilità dell’algoritmo di Reinforcement Learning potrebbe diventare un variabile importante.