PRIMO GRUPPO DI TEST
Come già detto, il primo gruppo di test è eseguito con la funzione di loss “Binary_Crossentropy” e gli otto valori disponibili degli ottimizzatori.
| Nr. Test | Valore Loss | Valore Optimizer | Accuracy Max | Colore Grafico | Batch Size |
| 1 | binary_crossentropy | adam | 0.8306 | grigio | 10 |
| 2 | binary_crossentropy | rmsprop | 0.8411 | arancione | 10 |
| 3 | binary_crossentropy | sgd | 0.8038 | blu | 10 |
| 4 | binary_crossentropy | adadelta | 0.3994 | rosso | 10 |
| 5 | binary_crossentropy | adagrad | 0.7469 | azzurro | 10 |
| 6 | binary_crossentropy | adamax | 0.8049 | viola | 10 |
| 7 | binary_crossentropy | nadam | 0.848 | verde | 10 |
| 8 | binary_crossentropy | ftrl | 0.651 | grigio scuro | 10 |
(Test accuracy max: binary_crossentropy e nadam).
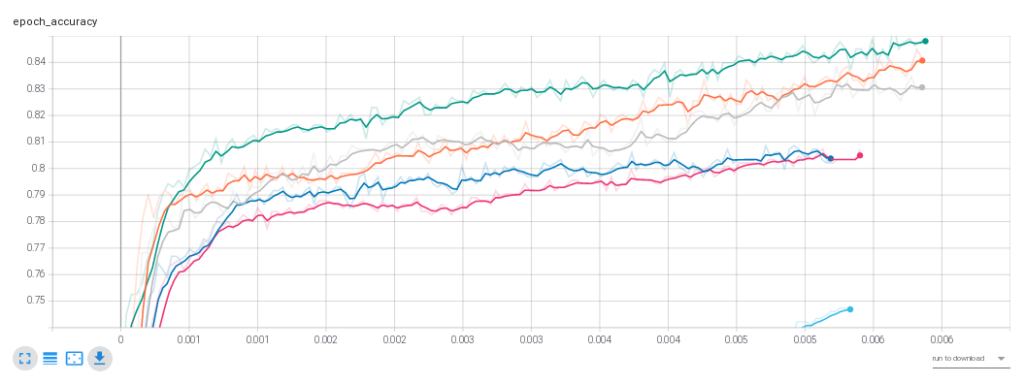
(Risultati dei primi test: Binary_Crossentropy e optimizer “Nadam”).
Come si vede dall’immagine, il valore più alto è quello raggiunto dalla combinazione (loss+optimizer) di colore verde. In tale situazione, la combinazione è la seguente: loss uguale a “Binary_Crossentropy” e optimzer “Nadam”.
SECONDO GRUPPO DI TEST
| Nr .Test | Valore Loss | Valore Optimizer | Accuracy Max | Colore Grafico | Batch Size |
| 1 | Hinge | adam | 0.8306 | arancione | 10 |
| 2 | Hinge | rmsprop | 0.8087 | blu | 10 |
| 3 | Hinge | sgd | 0.8005 | rosso | 10 |
| 4 | Hinge | adadelta | 0.651 | azzurro | 10 |
| 5 | Hinge | adagrad | 06756 | viola | 10 |
| 6 | Hinge | adamax | 0.8104 | verde | 10 |
| 7 | Hinge | nadam | 0.8289 | grigio | 10 |
| 8 | Hinge | ftrl | 0.651 | marrone | 10 |
(Test accuracy max: hinge e adam).
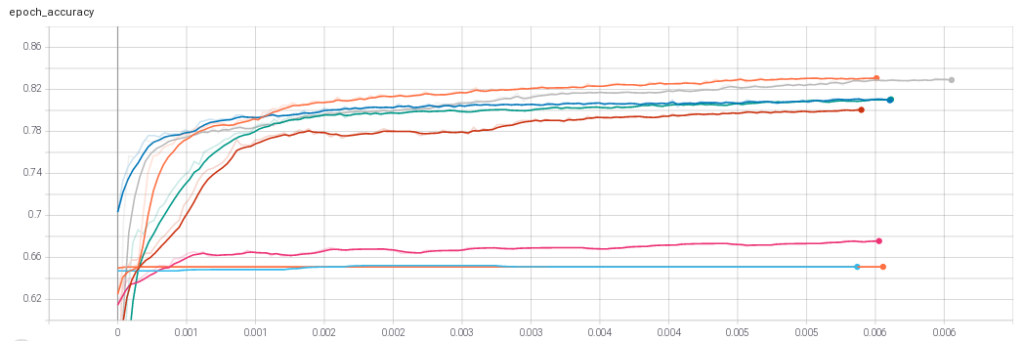
Risultati del secondo gruppo di test: Hinge e optimizer “Adam”.
TERZO GRUPPO DI TEST
| Nr. Test | Valore Loss | Valore Optimizer | Accuracy Max | Colore Grafico | Batch Size |
| 1 | Squared Hinge Loss | adam | 0.8306 | arancione | 10 |
| 2 | Squared Hinge Loss | rmsprop | 0.8097 | blu | 10 |
| 3 | Squared Hinge Loss | sgd | 0.8005 | rosso | 10 |
| 4 | Squared Hinge Loss | adadelta | 0.651 | azzurro | 10 |
| 5 | Squared Hinge Loss | adagraf | 0.6756 | viola | 10 |
| 6 | Squared Hinge Loss | adamax | 0.8104 | verde | 10 |
| 7 | Squared Hinge Loss | nadam | 0.8289 | grigio | 10 |
| 8 | Squared Hinge Loss | ftrl | 0.651 | marrone | 10 |
(Test accuracy max: Squared Hinge Loss e adam).
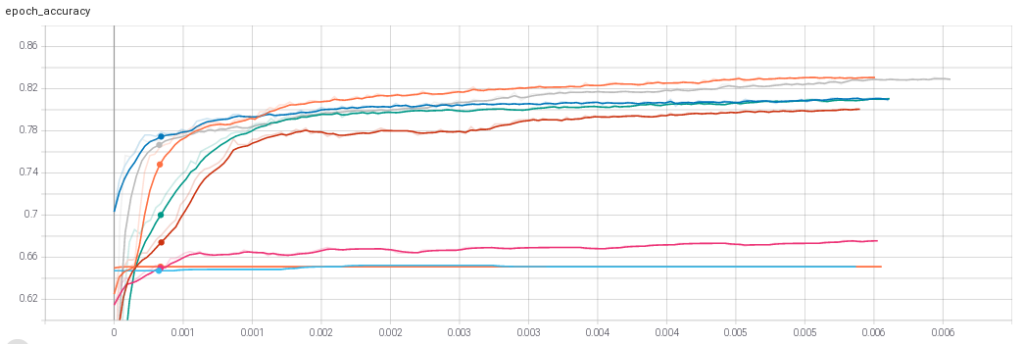
Risultati del secondo gruppo di test: “Squared Hinge Loss” e optimizer “Adam”.
Dai tests eseguiti evince come si raggiunge un valore migliore applicando la combinazione “Binary_Crossentropy” e ottimizzatore “Nadam”. Tale risultato è applicato ai dati di training e solo a quelli. Quindi, non è detto che nei dati di tests applicando tale combinazione si ottenga lo stesso risultato.
Pagina Precedente / Pagina Successiva
Un commento su “Il modello sequenziale di Keras: un esempio di utilizzo.”
Utile