SUDDIVISIONE DEL DATASET PRINCIPALE NEI DATASETS X e Y
A questo punto, suddividiamo il dataset principale diabetes in due dataset, il primo contenente le variabili indipendenti (X), e quindi, in pratica le prime otto colonne del dataset attuale, mentre il secondo contenente il dataset della variabile dipendente (Y). Tutto ciò, lo possiamo fare con poche righe di codice e più precisamente con le seguenti:
20 Y= diabetes.Outcome
21 X = diabetes.drop('Outcome',axis=1)
22 columns = X.columnsLa ventesima riga attribuisce al dataset Y la colonna Outcome, mentre la riga ventuno attribuisce al dataset X tutte le altre colonne dei dati tranne quella indicata con il nome Outcome. La terza riga attribuisce gli ‘headers’ di colonna alla variabile columns. La variabile columns quindi conterrà i seguenti dati:

(La variabile columns cosa contiene?)
LA STANDARDIZZAZIONE DEI DATI
Ora, utilizzeremo la classe StandardScaler per “scalare” i dati. Ma perchè dobbiamo “scalare” i dati? Essenzialmente dobbiamo scalare i dati per due ragioni. La prima è legata all’elaborazione dei valori che risulterebbe molto più veloce da parte degli algoritmi di Machine Learning. La seconda è connessa all’utilizzo di algoritmi basati sulla distanza e sugli alberi (regressione logistica, SVM e così via) che risentirebbero dei valori “anomali”, ossia dei valori più esterni delle “caratteristiche” del nostro dataset. Per caratteristica intendo le variabili del nostro dataset X. Con il codice seguente riusciamo a scalare i nostri dati.
23 scaler = StandardScaler()
24 XScaler = scaler.fit_transform(X)
25 dataXScaler = pd.DataFrame(XScaler, columns = columns)Nelle seguenti immagini sono visibili i dati non “scalati” del dataset X e i dati “scalati” del dataset XScaler.
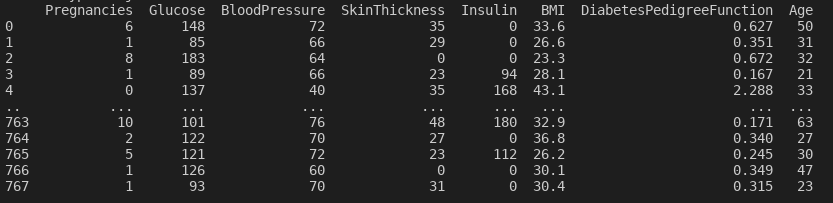
(Dati non scalati del dataset X)
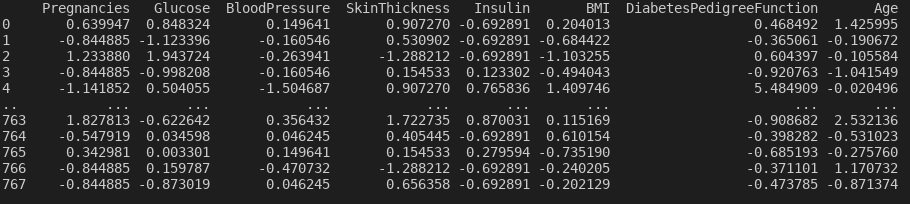
(Dati scalati del dataset XScaler)
Un commento su “Il modello sequenziale di Keras: un esempio di utilizzo.”
Utile