ANALISI DEI DATI
In questa parte di analisi dei dati vedremo come si distribuiscono i dati nei vari caratteri del dataset elencati precedentemente, tranne l’output ovviamente.
Iniziamo il lavoro di analisi dal primo carattere, e cioè, quello relativo al numero di volte che il paziente è rimasto “incinta” e quindi la relazione con la presenza o meno del diabete. Per far questo, utilizziamo la libreria Seaborn e in particolare il grafico a violino. Con le seguenti righe possiamo costruire tale tipo di visualizzazione.
16 graph1 = sea.violinplot(x='Outcome', y='Pregnancies', data=dataset, palette='muted', split=True)
17 plt.show()Nel codice Python, con la riga 16 si crea il grafico a violino dove in x si pone il risultato (0 non diabetico, 1 diabetico), mentre nell’asse delle y il dato di ‘Pregnancies’ di cui abbiamo già parlato precedentemente. Successivamente, per ogni caratteristica del dataset considerata costruiremo un grafico a violino.
Per leggere il risultato del grafico a violino dobbiamo chiederci:
“A seconda della caratteristica che sto considerando qual’è l’impatto sui soggetti diabetici e non diabetici?”
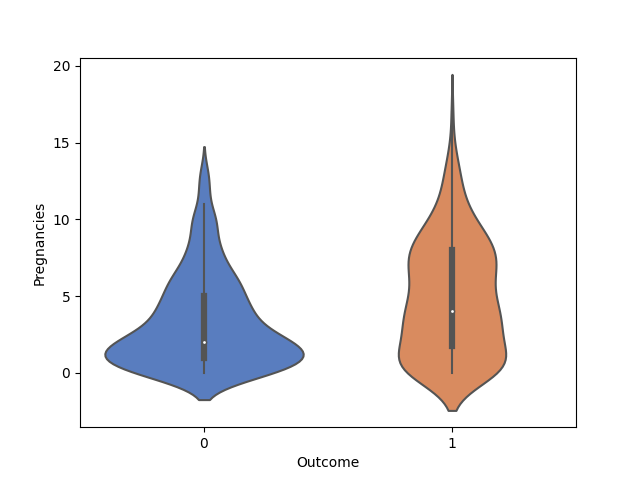
(Relazione tra maternità e diabete).
Il grafico mostra come nelle pazienti considerate, quelle con diabete sono rimaste più volte incinte di quelle senza diabete.
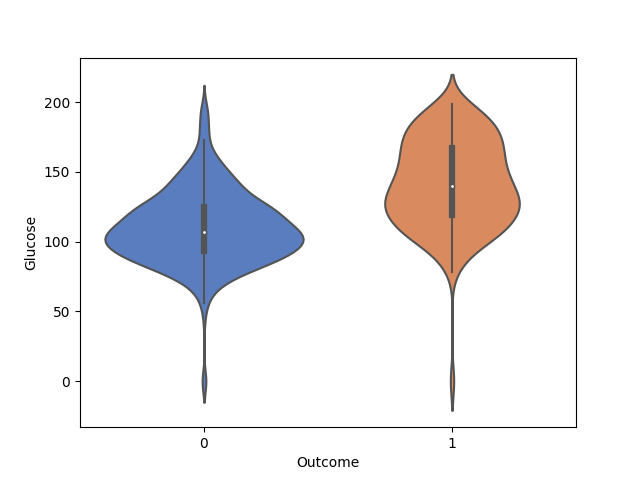
(Relazione tra diabete e concentrazione del glucosio).
In questo grafico, emerge come una alta concentrazione del glucosio sia presente nei casi con diabete. La concentrazione del glucosio risulta uno dei fattori di rischio per l’insorgenza del diabete.
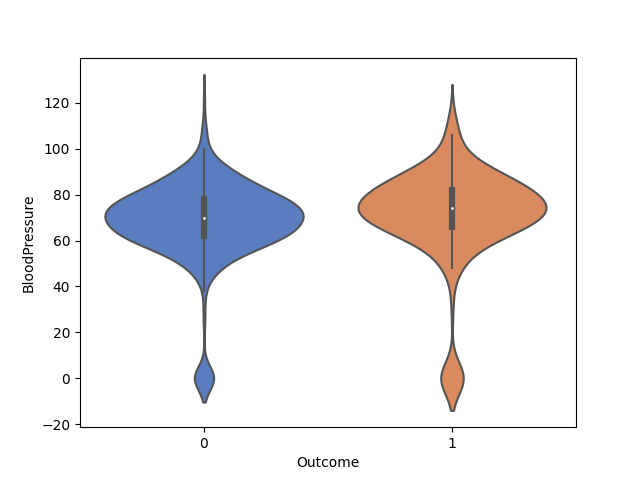
(La pressione sanguigna minima nei casi con e senza diabete).
Dal grafico precedente, si può vedere come i casi con diabete (grafico a violino arancione) abbiano una pressione sanguigna minima leggermente superiore ai quella dei casi che non hanno il diabete (grafico a violino di colore blu). Nel grafico, sono anche rappresentati quei i casi a cui corrisponde una pressione sanguigna minima a zero. A questi verrà attribuita una pressione sanguigna media.
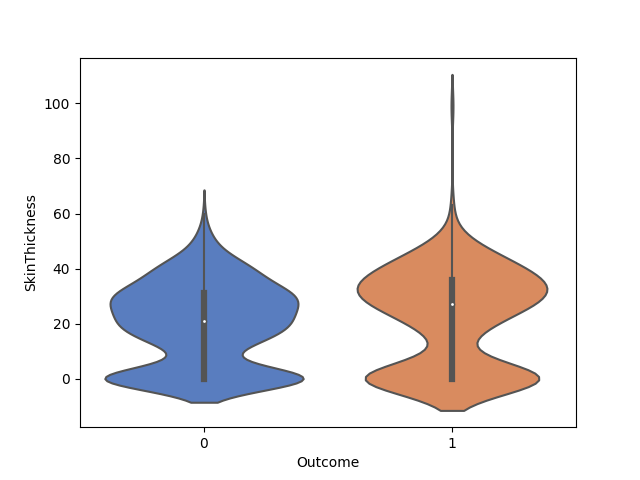
(Relazione tra lo spessore della piega cutanea del tricipite e il diabete)
Dal grafico, emerge come la piega cutanea del tricipite sia maggiore nei casi con diabete.
Un commento su “Il modello sequenziale di Keras: un esempio di utilizzo.”
Utile