La standardizzazione dei dati
Effettivamente la “standardizzazione applicata” in precedenza nella riga cinquantadue considera l’epurazione dai valori del vettore l della loro media. Essendo degli appunti, ho modificato la riga cinquantadue con la seguente:
l = (l-l.mean()) / np.std(l)
Come vedete ho aggiunto la parte al denominatore che non è altro che la deviazione standard dei valori del vettore l calcolata con l’aiuto del metodo std della classe Numpy. Ecco la formula della standardizzazione:
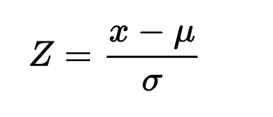
(Formula della standardizzazione).
Nella precedente x è un valore del vettore l, μ la media dei valori del vettore l e σ la deviazione standard dei valori l. Z non è altro che il valore standardizzato, anche chiamato punteggio Z.
Tutto questo, ci permette di ottenere dei valori ‘puri” adimensionali svincolati dall’unità di misura di partenza. Inoltre, abbiamo la possibilità di confrontare la variabile ‘Close’ con altre variabili con ordini di grandezza differenti.
Ora, vediamo come il tutto si traduce nel grafico dell’andamento della pair ETH/BTC.
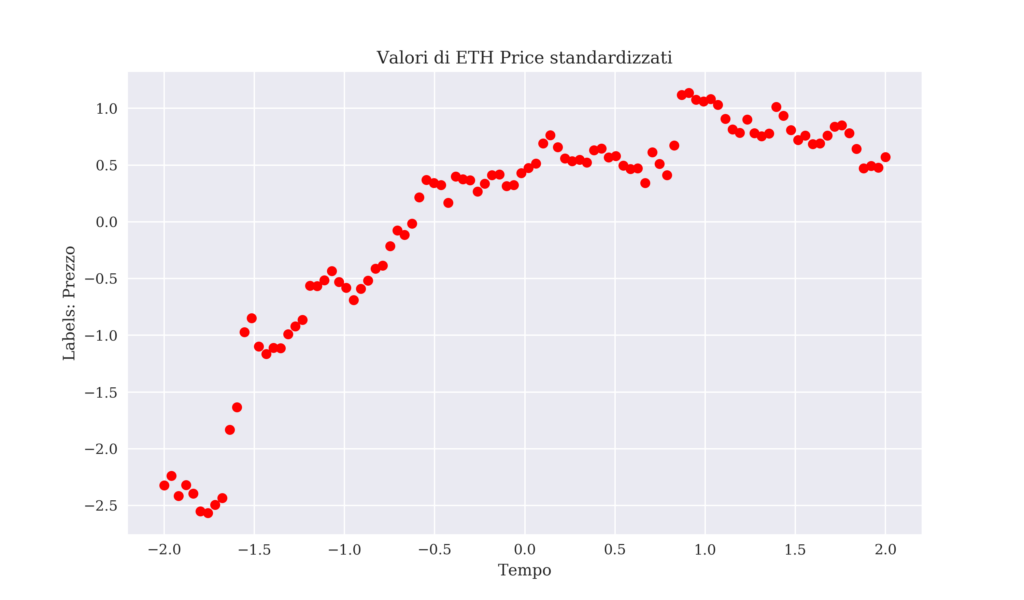
(Standardizzazione della variabile ‘Close’)
Conclusioni
In questa parte, abbiamo parlato del modello di regressione polinomiale e del metodo della standardizzazione. Nella prossima parte, vedremo l’ultima parte di codice relativa al modello di regressione polinomiale, e cercheremo di ottenere una prima previsione “grezza” del prezzo “Close”. A breve, aggiungeremo anche la parte relativa del codice in Python su Github per permettere a chiunque di poter sperimentare quanto visto finora.
Link alle parti precedenti degli appunti di Machine Learning:
Appunti di Machine Learning in ambito finanziario I parte.
Link alle parti seguenti degli appunti di Machine Learning:
Appunti di Machine Learning in ambito finanziario III parte.
Come al solito, per eventuali domande e integrazioni inviate un e-mail a webmaster@megalinux.cloud. Aiutate a sostenere The Megalinux, l’unico sito nel Web senza pubblicità inviando Bitcoin al seguente indirizzo.
3LpoukFpvDHTZPn5qGbLwUzve3rX9zsSq6
